Ler todo conteúdo definindo charset
Consome um arquivo previamente aberto para leitura a fim de ler todo seu conteúdo definido com uma determinada codificação de caracteres.
Parâmetros
| Nome | Tipo | Doc |
|---|---|---|
| Parâmetro 1 | Objeto | Objeto que faz referência a um arquivo aberto para leitura |
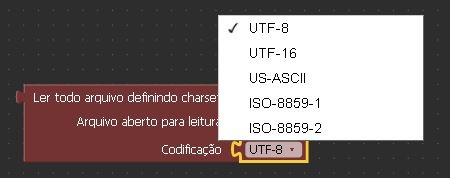
| Parâmetro 2 | String | Tipo de codificação |
Obs.:
O tipo de objeto esperado é o mesmo retornado pela função "Abrir arquivo para leitura"
Retorno
Retorna o conteúdo do arquivo no formato string.
Compatibilidade
 Servidor
Servidor
Exemplo 1
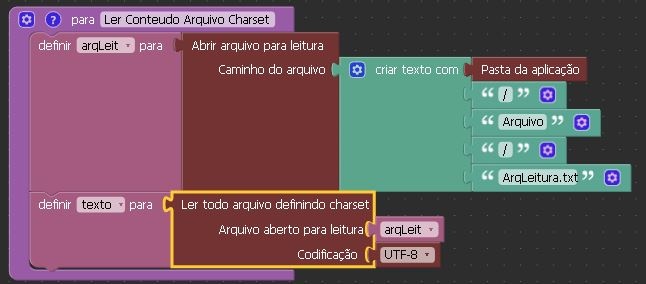
A função abaixo em destaque lê todo o conteúdo do arquivo definido com uma codificação de caracteres específica.
Sobre charset
Charset significa “conjunto de caracteres” (character set). Os charsets foram feitos como uma biblioteca de caratecteres que podem ser utilizados com propósitos gerais em computadores, softwares, browsers etc. Os charsets mais conhecidos são os da série ISO-8859 (ISO-8859-1, …, ISO-8859-10) e os da família Unicode (UTF-8, UTF-16). O charset indica o formato de codificação de caracteres utilizado em um documento.
Mais sobre
Sobre o bloco
A função utilizada para ler todo o arquivo contém cinco opções de codificação de caracteres: